Research Paper Implementations
From-scratch PyTorch implementations of cutting-edge AI research papers with detailed architectural breakdowns
Complete PyTorch implementation of PaLiGemma vision-language model combining Google's Gemma language model with SigLIP vision encoder. Features detailed architectural breakdowns, clean educational code, and comprehensive documentation for multimodal AI understanding.
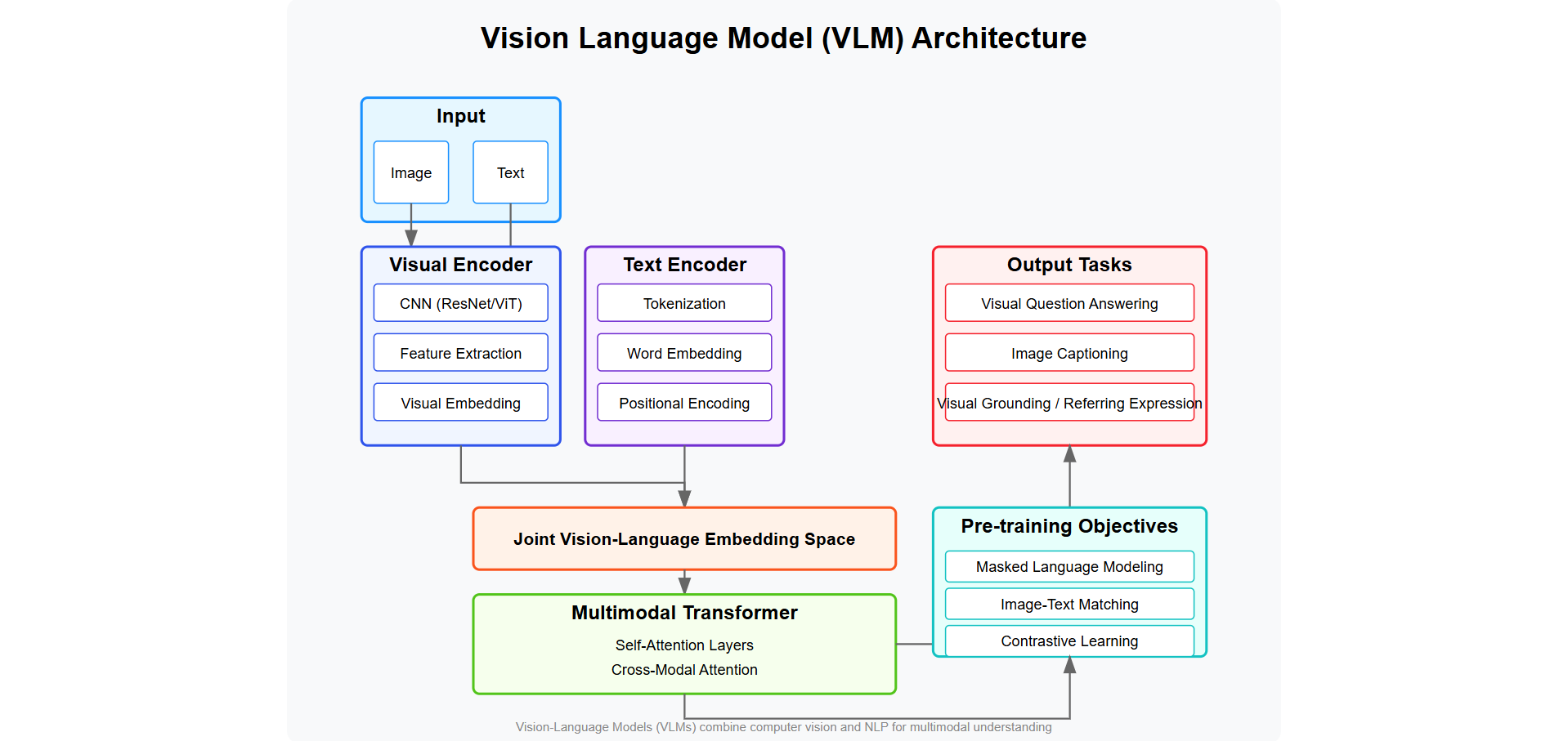
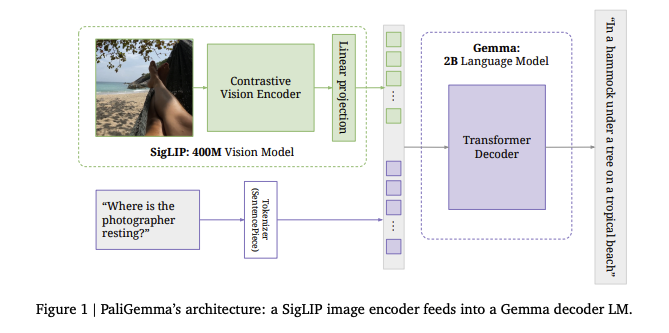
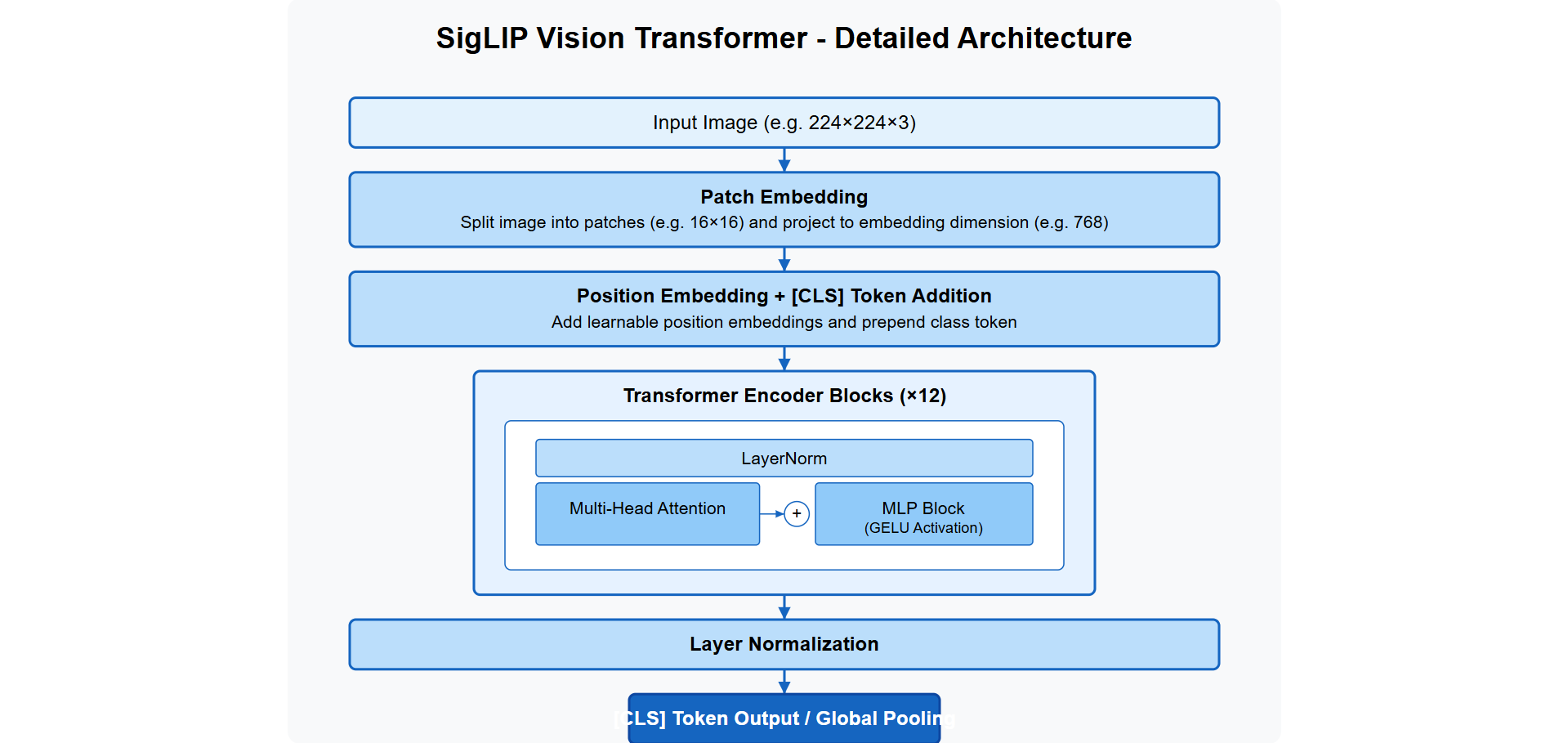
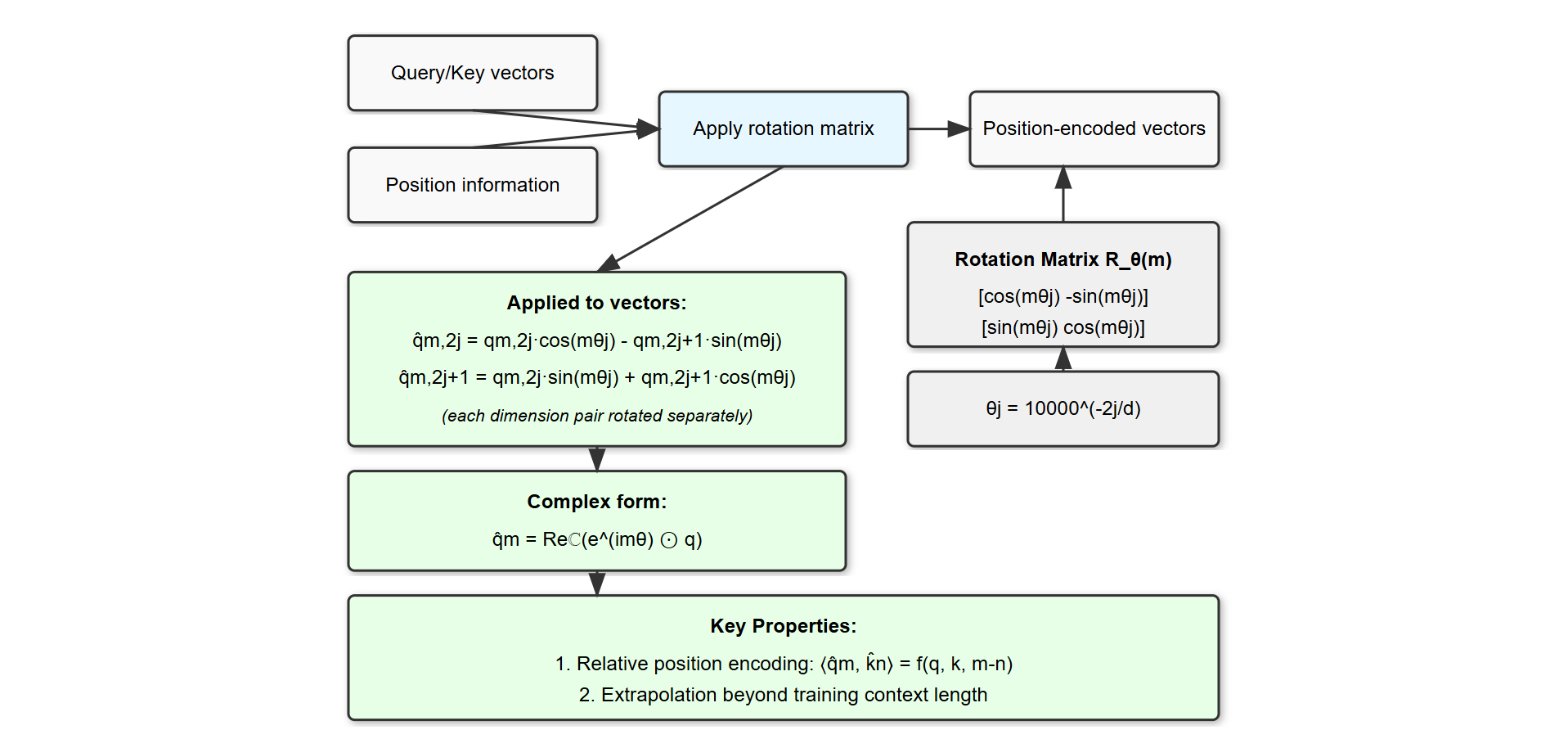
Architecture Components
- SigLIP Vision Encoder: Processes images into embeddings using Vision Transformer with 16×16 patches, generating 196 tokens for 224×224 images
- Gemma Language Model: Decoder-only architecture with RMSNorm, GeLU activations, Rotary Position Encoding (RoPE), and grouped-query attention
- Rotary Position Encoding: Sophisticated position encoding applying rotation matrices to query/key vectors
- KV-Cache Mechanism: Efficient autoregressive inference with cached key-value pairs for faster generation
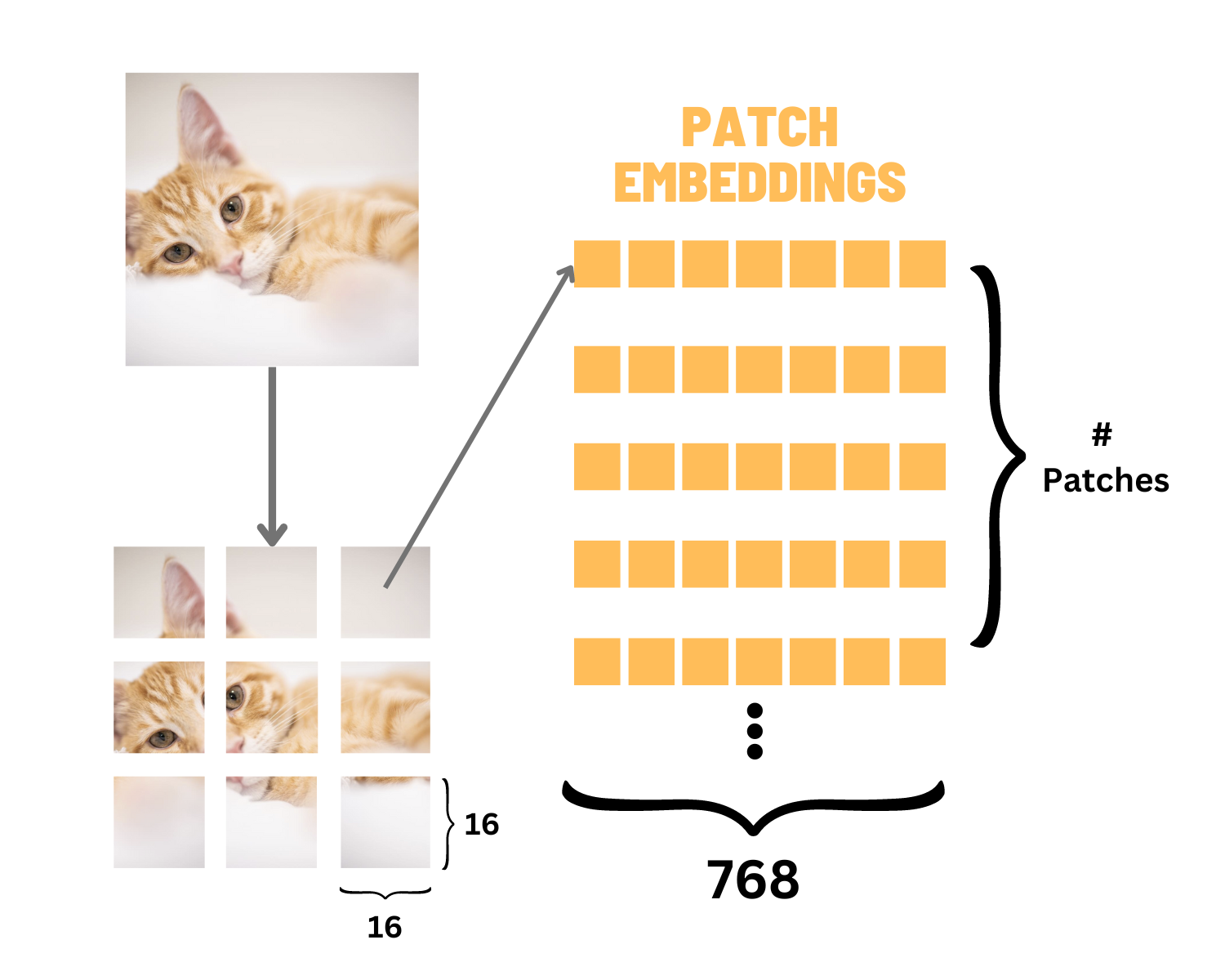
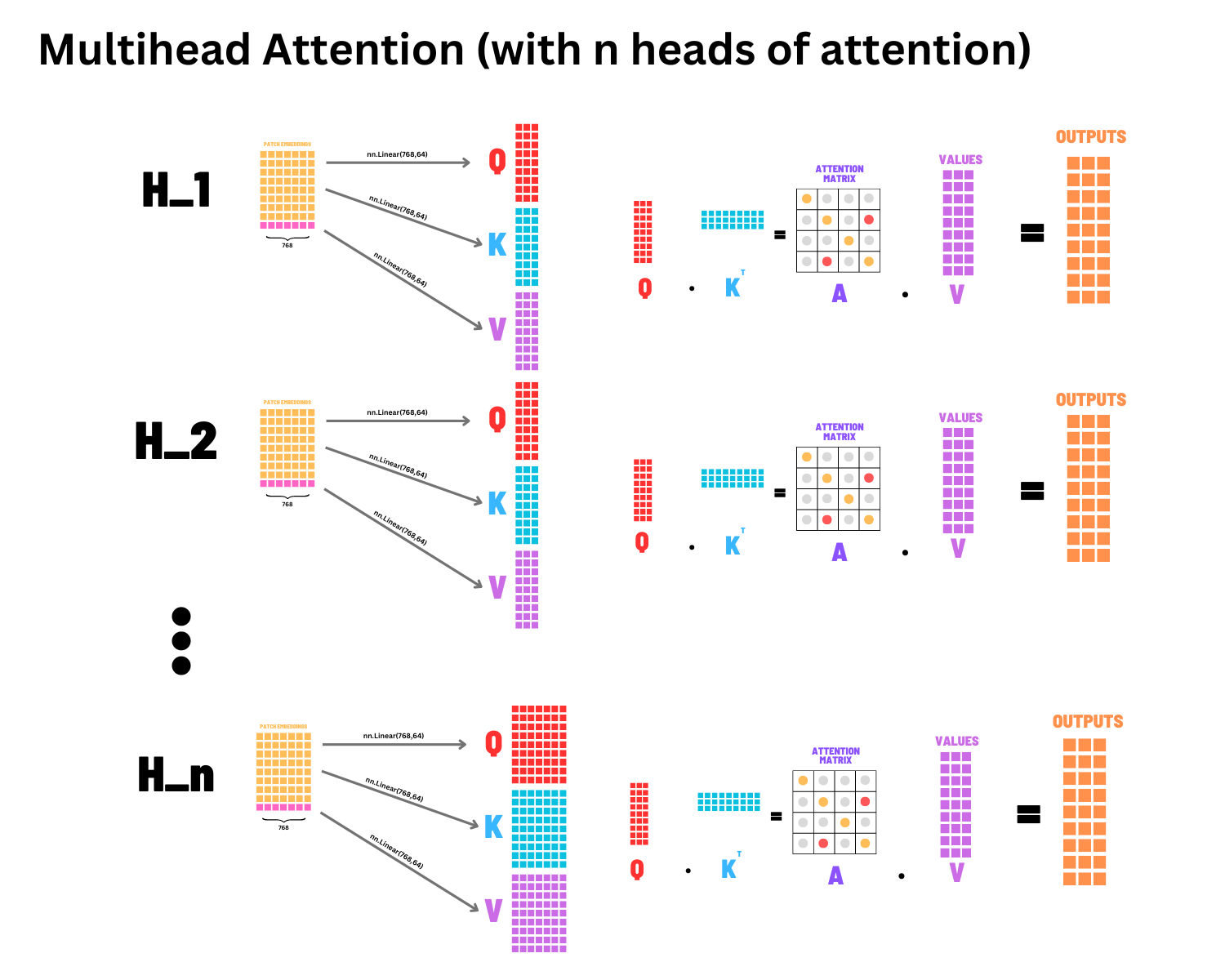
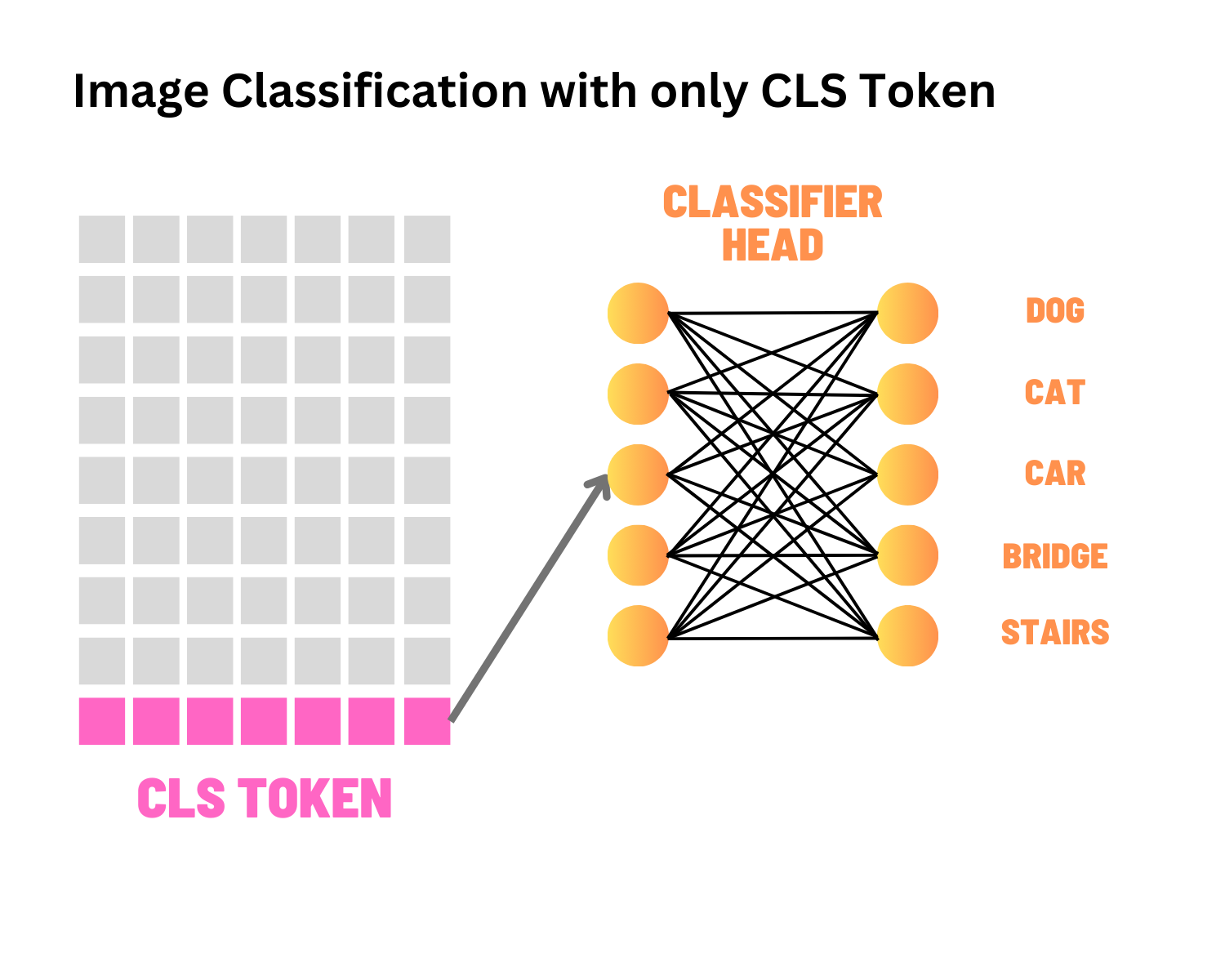
Complete PyTorch implementation of Vision Transformer from "An Image is Worth 16x16 Words" paper. Includes training pipelines for CIFAR-10 and ImageNet with patch embedding, multi-head self-attention, position encodings, and comprehensive architectural visualizations.
Architecture Implementation
- Patch Embedding: Divides images into 16×16 non-overlapping patches, linearly projects to embedding dimension using Conv2d for efficiency
- Multi-Head Self Attention: Jointly attends to information from different representation subspaces with scaled dot-product attention
- MLP Block: Feed-forward network with GELU activation applied after attention mechanism
- Class Token: Learnable embedding prepended to sequence for classification, similar to BERT's [CLS] token
Pure PyTorch implementations of LoRA and QLoRA for memory-efficient fine-tuning of large language models and vision transformers. Features custom training scripts, 4-bit quantization, and practical examples achieving 65-85% memory reduction while maintaining performance.



LoRA Architecture
- Low-Rank Adaptation: Injects trainable rank decomposition matrices (A, B) into frozen pre-trained weights W
- Parameter Efficiency: Trains <1% of parameters with rank r typically 8, 16, or 32
- Memory Reduction: 65% reduction for BERT, 50% for LLaMA-7B
QLoRA Innovations
- 4-bit NF4 Quantization: Normal Float data type optimized for LLM weight distributions
- Double Quantization: Quantizes quantization constants for additional memory savings
- Memory Efficiency: 85% reduction enabling LLaMA-65B fine-tuning on consumer GPUs
Core concepts of reasoning in Large Language Models implemented from scratch. Explores inference-time compute scaling, reinforcement learning approaches, chain-of-thought mechanisms, and advanced reasoning techniques for building more capable AI systems.
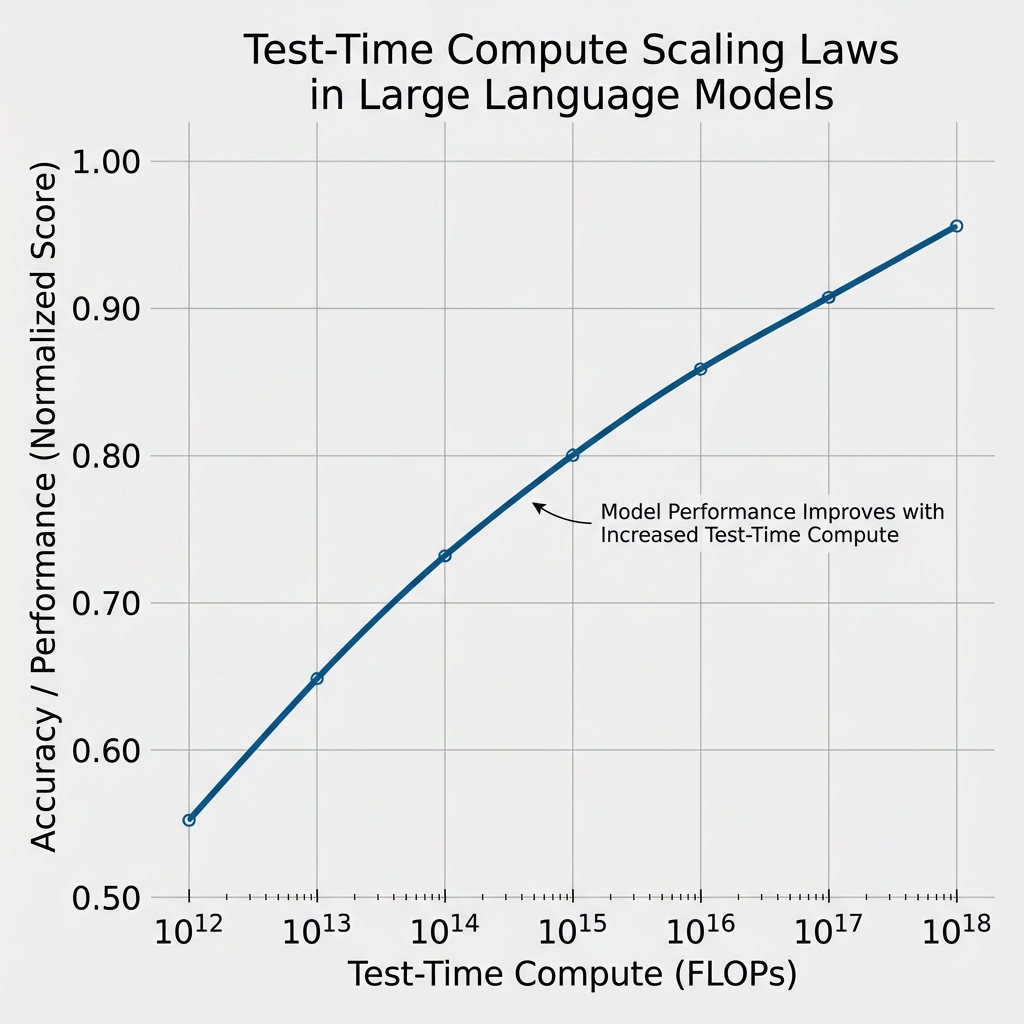
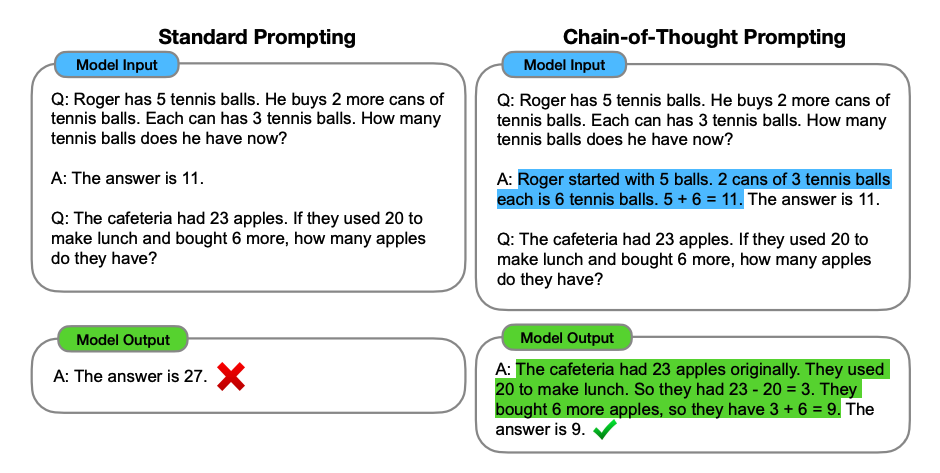
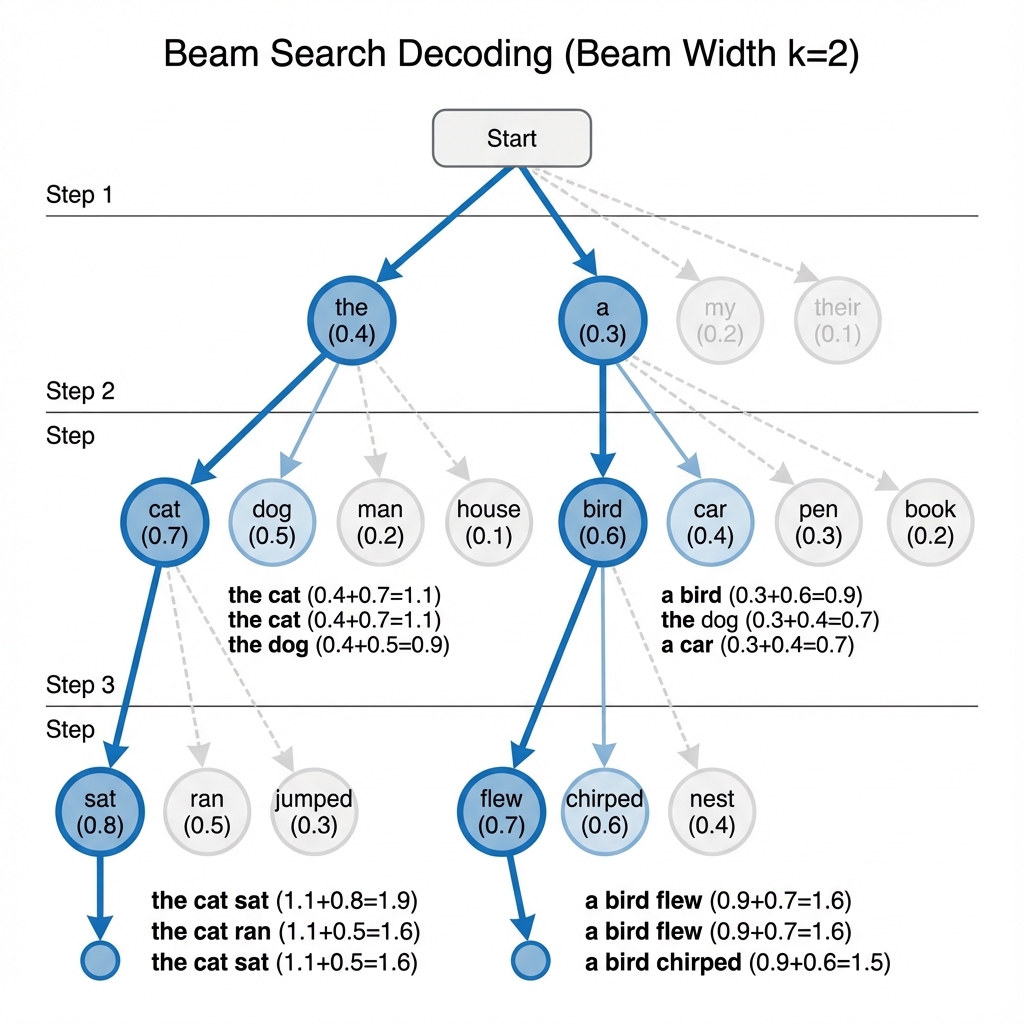
Inference-Time Compute Scaling
- Zero-Shot Prompting: Applied to Llama 3.2 built from scratch for baseline reasoning capabilities
- Beam Search: Demonstration of search-based decoding strategies for improved output quality
- Chain-of-Thought: Multi-step reasoning with explicit thought process